Chrome の SameSite 属性の仕様によりアプリケーション不具合が起きた話
これは エキサイトホールディングス Advent Calendar 2023 の3日目の記事です。
最近は業務でたまに PHP を書いているのですが、Chrome の SameSite 属性の挙動により四苦八苦したのでその内容をまとめてみようと思います。
結論
先に結論です。
前提として、Chrome ブラウザに限った話です。Firefox など他のブラウザでは微妙に仕様が異なります。
Cookie に設定できる SameSite 属性に Lax を設定していると、Cross Site な POST リクエストを利用する場合は Cookie が発行されてから 2分間だけその POST リクエストに Cookie がセットされます。2分を過ぎると POST リクエストには Cookie がセットされなくなるので、アプリケーションの挙動としておかしくなる可能性があります。
SameSite=None を利用するか、POST を GET にするか、Cookie を利用しないようにするか、Cookie の発行タイミングを調整するなどの対応を取る必要があるでしょう。
SameSite 属性と Chrome の仕様
自分が四苦八苦したケースを説明する前に簡単に SameSite 属性と SameSite に対する Chrome の仕様の説明をしておきます。今回の事象を解説するための最低限の説明なので詳しくは参考 URL などをご覧ください。
Same Site の条件
以下の全てが一致すれば Same Site となり、1つでも異なれば Cross Site です。
- スキーマ(
http,httpsなど) - eTLD + 1 (例:
example.co.jp,example.comなど)
※ eTLD(effective Top Level Domain) とは、.comや.orgなど Root Zone Database に掲載されてるTLD とそのすぐ左側を合わせたものです。.co.jpや.github.ioなど、実質的にTLDとして扱われてるものもあり、これらは Public Suffix List にまとめられています
例えば、https://sub1.example.com と https://sub2.example.com は Same Site であり、https://example1.com と https://example2.com は Same Site ではありません。
SameSite 属性について
Cookie を発行する際に設定できる SameSite 属性は 3 つの値を設定できます。
| 設定値 | 説明 |
|---|---|
| None | 全ての cross-site なリクエストに対して Cookie が付与されます |
| Strict | same-site に対するリクエストにのみ Cookie が付与されます |
| Lax | GET リクエストでの Cross Site のページ遷移や Same Site の POST, GET リクエストにのみ Cookie が付与されます。一方、POST メソッドのような CSRF の危険性が高い HTTP メソッドによる Cross Site なリクエストに対しては Cookie が付与されません。Cross Site で POST リクエストする場合は Cookie が飛ばないので悪意のあるサイトからの POST による CSRF 攻撃の対策になります。 |
※ ちなみに、Chrome 84 以降 SameSite 値が設定されていない Cookie は SameSite=Lax として扱われるようになりました
SameSite 属性に関する Chrome の仕様
Chrome では SameSite=Lax かつ Cross Site な POST リクエストをした際の挙動が上記で説明した Lax の挙動と少し異なります。 それは、Cookie が生成されたタイミングから2分以内であれば Cross Site な POST リクエストに Cookie が付与され、2分以降は Cookie を付与しないという点です。
実際に自分が遭遇したケースを見てみましょう。
不具合が起きたケース
PHP で他社システムにリダイレクトをしながら行うある登録処理を開発をしていたときに、Chrome で登録処理が成功したり失敗したりする現象にあいました。
A サイトを自社で管理するサイト、B サイトを他社で管理するサイトとして、その処理の流れを下記に示します。前提としてユーザが A サイトにログイン済みでセッションIDが SameSite=Lax で Cookie にセットさているものとします。
- A サイトでユーザが情報を入力し POST リクエストを送信
- A サイトで登録処理のトランザクションIDを発行しキーバリューストアにセッションIDをキーとしてトランザクションIDを登録
- B サイトへリダイレクト
- B サイトでももろもろの処理後に A サイトへ POST リクエストのリダイレクト
- キーバリューストアからセッションIDをキーとしてトランザクションIDを取得
- トランザクションIDを利用して登録処理実施

A サイトと B サイトは完全に別ドメインなので Cross Site となります。また、B サイトから A サイトへのリダイレクトは POST リクエストなので今回紹介した仕様にあてはまります。起こる現象としては、セッションIDがセットされた Cookie が発行されるのはログインの時なので、ログインから2分以内に A サイトにリダイレクトで戻ってこれるとその A サイトへの POST リクエストに Cookie が付与され、キーバリューストアからトランザクションIDを取得することができ登録が成功します。しかし、ログインから2分以降に A サイトにリダイレクトで戻ってくるとその POST リクエストには Cookie がセットされていないので、サーバ側にセッションIDが伝わらずキーバリューストアからのトランザクションIDの取得に失敗します。
対応方法
対応としては以下の方法があるかと思います。
今回はアプリケーション側で CSRF 対策をした上で 3 の SameSite=None で対応しました。
また、今回紹介した Lax + POST の組み合わせによる2分縛りはいずれなくなり、2分経過することなく Cookie がセットされなくなるようです。時間をリセットするためにセッションIDを再生成して Cookie に設定し直す方法もあるかとは思いますが、いつ仕様が変わるか分からないのでこの方法は取りませんでした。 https://www.chromium.org/updates/same-site/
Note that the 2-minute window for "Lax+POST" is a temporary intervention and will be removed at some point in the future (some time after the Stable launch of Chrome 80), at which point cookies involved in these flows will require
SameSite=NoneandSecureeven if under 2 minutes old.
まとめ
今回は Chrome の SameSite 属性仕様によるアプリケーションの不具合事例を紹介しました。 過去に SameSite 属性の仕様変更があった際にこの2分の仕様が色々な記事で投稿されていましたが、今回の件で自分が詰まったときになかなかそれらの記事に辿り着けませんでした。さまざまな技術動向にアンテナを貼ることは大事だと改めて感じました。 今回の記事が自分のような人に届けば幸いです。
参考URL
やりつくされた IAM アクセスアドバイザーの紹介をあえてやる
これは エキサイトホールディングス Advent Calendar 2022 の21日目の記事です。
みなさん、AWS を利用していて IAM の最小権限を割り当てるって難しくない?と思ったことはありませんか。そんな時は IAM アクセスアドバイザーが便利ですよね。ネット上に IAM アクセスアドバイザーについての説明はごろごろありますが、あまり目立たない機能なのであえて紹介してみたいと思います。
IAM アクセスアドバイザーとは
IAM アクセスアドバイザーとは、IAM リソースがアクセス可能なサービスや IAM リソースの過去のアクセス履歴などの情報を提供してくれる IAM の機能です。この機能はマネージメントコンソール上で利用したり、API が提供されているので CLI で利用したりすることができます。
どんな時に役に立つか
権限を整理し最小権限に近づけることができます。例えば、高権限な IAM ポリシーを持った IAM ロールが存在しているが、その IAM ロールが利用しているサービスが限定されていることが分かれば、割り当てているポリシーを見直すきっかけになるでしょう。
他にも、簡易的な監査に利用できます。例えば、意図していない AWS サービスにアクセス可能となっていないか確認できたり、過去一定期間でアクセスした AWS サービスの履歴の表示をできたりします。なおサービスの追跡期間は過去 400 日間です。十分すぎますね。
実例
マネージメントコンソール上での見え方を紹介します。まず、IAM サービスに移動して適当に IAM ユーザや IAM ロールを1つ選択します。そうすると画面中央あたりに「アクセスアドバイザー」というタブがあるので押下すると下記のような画面が出るかと思います。

ここでは、選択した IAM エンティティが過去に利用したサービス一覧と日付が表示されています。ここを見れば、普段から使用している・使用していないサービスを把握することができます。つまり、使用していないサービスが見つかれば、そのサービスに対する権限を剥奪することにより、最小権限な IAM ポリシーを作成することができます。
さらに、EC2, IAM, S3, Lambda サービスについてはリンクになっており、飛び先でより詳細な情報を確認できます。今回は EC2 の画面を見てみます。EC2 を押下した画面が下記となっています。
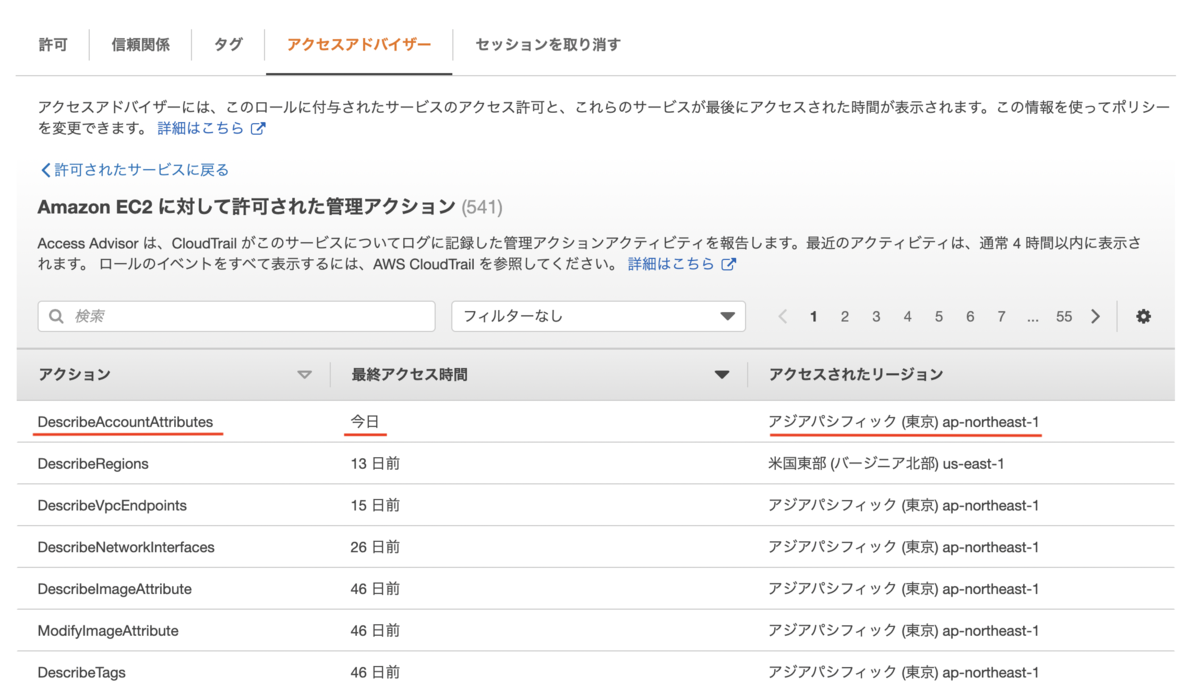
EC2, IAM, S3, Lambda サービスについてはアクションごとにアクセス時間とアクセスリージョンを表示してくれます。ここではサービスのどのアクションを普段から使用している・使用していないかを確認できます。つまり、使用していないアクションが見つかれば、そのアクションの権限を剥奪することで、より最小権限な IAM ポリシーを作成することができます。
どうしても適切な IAM ポリシーの作成に困ったら少しだけ緩めに権限を作成し、数日後に実際に IAM エンティティが利用しているサービス(EC2, IAM, S3, Lambdaに限る)のアクションが分かるのでそのタイミングで最小権限な IAM ポリシーを設定するといった方法もとれますね。
まとめ
簡単ではありますが、今回は IAM アクセスアドバイザーを紹介しました。
あまり目立たない機能ですが、権限整理にはもってこいの機能ですし追加料金もかからないので、ぜひ使ってみてはいかがでしょうか。
2022年の AWS IAM Identity Center の進化を振り返ってみよう
これは エキサイトホールディングス Advent Calendar 2022 の4日目の記事です。
業務上、AWS IAM Identity Center(旧AWS Single Sign-On)をよく使うので、この記事では 2022 年の AWS IAM Identity Center 関連の嬉しいアップデートを振り返ろうと思います。ただし、re:Invent 2022 の内容は入っていません。 また AWS IAM Identity Center は名称として長いので、以降の文章内では IIC と省略させていただきます。
- AWS IAM Identity Center とは
- AWS IAM Identity Center が大阪リージョンで利用可能に
- 組織内で委任されたメンバーアカウントからの AWS IAM Identity Center の管理
- AWS IAM Identity Center が AWS Identity and Access Management (IAM) カスタマー管理ポリシー (CMP) のサポートを追加
- IAM アイデンティティセンターがユーザーエクスペリエンスとクラウドセキュリティ向上のため、セッション管理機能を追加
- 大規模にユーザーとグループを管理する、新しい AWS IAM Identity Center API を発表
- まとめ
AWS IAM Identity Center とは
アップデートを紹介する前に簡単に IIC を説明させてください。 IIC は「どのユーザーがどの AWS アカウントにどの権限でログインするか」ということを一元管理する目的で利用する AWS のサービスです。 IIC を使用してユーザーやグループを 1 か所で作成したり接続したりすることで、従業員のサインインセキュリティを管理できます。 AWS Organizations を利用して複数の AWS アカウントを運用している企業では重宝するサービスかと思います。
また、今年の 7 月には AWS Single Sign-On (AWS SSO) というサービス名自体が AWS IAM Identity Center に変わりました。個人的な話ですが、最近やっとアイデンティティセンターという呼び方に慣れてきました。
AWS IAM Identity Center が大阪リージョンで利用可能に
IIC が大阪リージョンで利用可能になりました。 弊社では BCP 対策として東京リージョン以外のリージョンを検討しているところで、リージョンを選択する上で IIC の大阪リージョン上陸は好材料となりました。
大阪リージョンの利用を検討している方にとっては良いアップデートかと思います。
組織内で委任されたメンバーアカウントからの AWS IAM Identity Center の管理
AWS Organizations で組織を管理している場合、組織の親 AWS アカウントが存在します。AWS のベストプラクティスとしては、親 AWS アカウントでは親 AWS アカウントで必要となる AWS サービスのみを利用し、親 AWS アカウントで扱う必要のない AWS サービスは組織内の別 AWS アカウント(以降、子 AWS アカウントと呼びます)に委任しましょうということになっています。親 AWS アカウントから AWS サービスの利用権限を委任された子 AWS アカウントのことを委任管理者アカウントと呼びます。
今回のアップデートで IIC を委任管理者アカウントで利用できるようになりました。ベストプラクティス通り、親 AWS アカウントでできるだけ AWS サービスを利用しないようにしている企業にとっては良いアップデートだったのかと思います。弊社も親 AWS アカウントではなく、委任管理者アカウントで IIC を運用するようにしました。
AWS IAM Identity Center が AWS Identity and Access Management (IAM) カスタマー管理ポリシー (CMP) のサポートを追加
今まで IIC でログインユーザのポリシーを管理するには、親 AWS アカウントもしくは委任管理者アカウントでインラインポリシーを指定する必要がありました。しかし、このアップデートにより、カスタムポリシーや許可の境界用のポリシーを子 AWS アカウントで作成し管理することができるようになりました。このアップデートにより、親 AWS アカウントもしくは委任管理者アカウントでコントロールしたい権限は引き続き今まで通りインラインポリシーを使用し、子 AWS アカウントで管理しても問題ないユーザの権限はカスタムポリシーや許可の境界用のポリシーを使用して子 AWS アカウントで管理することができます。
ユーザの権限管理を子 AWS アカウントに委任することができるようになり、権限管理の柔軟性が上がった良いアップデートだったかと思います。
IAM アイデンティティセンターがユーザーエクスペリエンスとクラウドセキュリティ向上のため、セッション管理機能を追加
このアップデートでユーザのセッション時間の調整が15分〜7日間でできるようになり、それに加えて個別のユーザセッションを終了することも可能となりました。企業のセキュリティーポリシーにもよりますがセッション時間を長めに設定しておくと、ユーザがいちいち毎日ログインしなければならないみたいなことが避けられますね。ユーザセッションの無効化については、何かあったときにユーザを強制的にログアウトさせることができますが、ログアウトまで最長1時間かかるので即時ログアウトにならない点は注意が必要です。
タイトル通り、ユーザーエクスペリエンスとクラウドセキュリティが向上した良いアップデートだったかと思います。
大規模にユーザーとグループを管理する、新しい AWS IAM Identity Center API を発表
これまで Get や List などの取得系の API しか存在しなかったのですが、このアップデートにより作成・削除・更新系の API も増えました。これにより IIC で管理しているユーザの作成や削除などのワークフローが組みやすくなり、入退社時の人の出入りやユーザの棚卸しなどが自動化できるかもしれません。
ユーザ管理の自動化のようなワークフローを組めるようになる良いアップデートだったかと思います。
まとめ
AWS IAM Identity Center に関する 2022 年のアップデートの中で役に立ちそうなものを紹介しました。 AWS IAM Identity Center を利用している企業において、今回紹介したアップデートで既存の問題が解消された!なんてことがあれば幸いです。 他にも AWS IAM Identity Center のアップデートはありますので、What's new でこの機会に振り返ってみるのもいいかもしれません。
EC2 Image Builder で作成した AMI が OU 単位で共有できるようになった話
これは エキサイトホールディングス Advent Calendar 2021 の25日目の記事です。
みなさん,AWS Organizations と EC2 Image Builder は使っていますでしょうか.AWS Organizations はマルチアカウントを一元的に管理し統制できるサービスです.そして,EC2 Image Builder は Amazon マシンイメージ(AMI)の構築フローを自動化するサービスです.AWS Organizations は AWS のさまざまなサービスと連携することでどんどん便利になってきており,最近のアップデートで EC2 Image Builder と連携して AWS Organizations が管理する各 AWS アカウントへの AMI の共有が容易になったので,今回はその紹介をしたいと思います.アップデートが発表された 2021/11/24 からつい最近までは AWS CLI でしか設定ができなかったのですが,マネージメントコンソールからも設定できるようになっていたのでマネージメントコンソール上での設定を紹介します.
AWS Organizations とは
AWS Organizations は組織のマルチアカウント運用に利用されるサービスで,アカウントの一元管理や各アカウントの統制などに役立ちます.
一般的に,管理するアカウントとなる親アカウントと管理されるアカウントとなる子アカウントで分けて,アカウント管理チームは親アカウントを利用してアカウントを一元管理する構成が多いかと思います.AWS Organizations は他の数多くの AWS のサービスと連携しているため,子アカウントの AWS サービスの設定を親アカウントで一括設定する使い方ができます.また,AWS Organizations では Organization Unit(OU) と呼ばれるアカウントをグループ化する機能を利用してアカウントを管理することができ,ガバナンス目的でそれらの OU に対して「S3 のパブリック公開を禁止する」のようなポリシーを適用することもよくある使い方です.

EC2 Image Builder とは
EC2 Image Builder は AMI の構築フローを自動化するサービスです.
AMI は事前構成された OS イメージで,EC2 インスタンスを作成するために必要な OS とソフトウェアを含んでいます.サービスに必要なパッケージやミドルウェアの設定などをカスタムして AMI を作成し,カスタムした AMI から EC2 インスタンスを起動することでサービス提供可能な EC2 インスタンスを迅速に用意できます.このような目的でカスタムされた AMI をゴールデンイメージと呼ぶこともあります.
ゴールデンイメージを利用する場合,OS のバージョンアップやパッケージの脆弱性対応などさまざまな理由でゴールデンイメージを作り直すことがあり,その都度新しいイメージを構築・テストして必要な環境へイメージを共有しなければなりません.その一連のプロセスをサービス化したのが EC2 Image Builder です.
ここでは EC2 Image Builder の詳細は割愛しますが,用語のざっくりとした解説と AMI の構築フローを図にしておきます.
- イメージレシピ:ミドルウェアや各種サーバの設定を定義した AMI を構築する手順書
- インフラストラクチャー:AMI を構築する環境
- ディストリビューション:AMI の配布先の設定
- ビルドスケジュール:AMI をビルドするスケジュール設定
- パイプライン:上記をまとめた AMI を構築する一連の手順のこと

アップデートの概要
今回のアップデートにより AWS アカウントにゴールデンイメージを配布することが容易になりました.従来の機能で実現できていた手法と今回のアップデートでできるようになったことを説明します.
従来可能であった運用
従来までは以下 2 つの方法で AMI を他アカウントに共有できていました.
- AMI の許可設定を変えて共有する
- EC2 Image Builder 上で設定するパイプラインを AWS Resource Access Manager と AWS Organizations を利用して共有する
前者の場合は,作成されたカスタム AMI の許可設定に 特定の AWS アカウント ID を指定することで他の AWS アカウントに AMI を共有する仕組みです.これは組織が管理しているアカウントが少なければよいですが,数が多くなってくるとアカウントの数だけ許可設定を追加しないといけないので別途 AWS Lambda を使ってプログラムを書いて自動化していくことになるかと思います.現状の運用はこの方法なのですが,AWS Lambda を書いてなんとか頑張るのは他の方法がなかったときの最終手段にしたい気持ちがあります.
後者の場合は,EC2 Image Builder 上で設定するパイプライン自体を共有することを意味しています.AWS のリソース共有を管理する AWS Resource Access Manager というサービスと AWS Organizations を使って OU 単位で共有が可能なのですが,子アカウントでは共有されたパイプラインを EC2 Image Builder で実行して AMI を作成しなければならず,単純に AMI を共有するよりステップが 1 つ増えてしまいます.可能であれば子アカウントの利用者に運用負荷を与えたくないので採用しませんでした.
新しく可能となった運用
今回のアップデートでは EC2 Image Builder と AWS Organizations が連携することにより,パイプラインの流れの中で指定した OU に AMI を共有できる機能が実装されました.具体的には,下図のようにパイプラインの中のディストリビューションフェーズで AMI をどこの OU に配布するか設定できます.

これにより,OU 配下のアカウントに対して AWS Lambda を使わず AMI を共有できるようになりました!
また,OU を使って AMI を共有できるようになるので,OU にアカウントを「入れる・外す」のアクションが AMI を共有「する・しない」の状態に紐づきます.注意点としては,ディストリビューションで OU を設定したパイプラインを一度実行して AMI を作成しないと AMI の共有は機能しないので,ディストリビューションを設定しただけで終わらないようにお気をつけください.
まとめ
NameSpace 機能を使ったネットワークからインターネットに出れなかった話
コンテナのネットワーク周りを理解するためにカーネルの NameSpace 機能を使って Ubuntu20.04 サーバ上に仮想的なネットワークを構築してみた.その際,作成したネットワークからインターネットに出るのに四苦八苦したのでメモとして残しておく.この記事では,ネットワークの構築の詳細は話さず構築後のトラブルシュートをメインとする.
概要
NameSpace 機能を使ったコンテナネットワークの実験をした.同じような実験についてはインターネットにいくつか記事があるが,今回は以下の記事を参考にした.
構築した環境は図のようになっている.

上記ネットワークを構築するコマンドをまとめておいた.もしよければどうぞ.
クリックすると展開されます
#!/bin/bash ip netns add host1 ip netns add host2 ip netns exec host1 ip link set lo up ip netns exec host2 ip link set lo up ip link add name veth1 type veth peer name br-veth1 ip link add name host1 type veth peer name br-host1 ip link add name host2 type veth peer name br-host2 ip link set host1 netns host1 ip link set host2 netns host2 ip link add br0 type bridge ip link set dev br-veth1 master br0 ip link set dev br-host1 master br0 ip link set dev br-host2 master br0 ip addr add 10.0.0.100/24 dev veth1 ip netns exec host1 ip addr add 10.0.0.1/24 dev host1 ip netns exec host2 ip addr add 10.0.0.2/24 dev host2 ip netns exec host1 ip link set host1 up ip netns exec host2 ip link set host2 up ip link set veth1 up ip link set br-veth1 up ip link set br-host1 up ip link set br-host2 up ip link set br0 up echo 1 > /proc/sys/net/ipv4/ip_forward ip netns exec host1 ip route add default via 10.0.0.100 ip netns exec host2 ip route add default via 10.0.0.100
また,環境としては EC2 の Ubuntu20.04 を使ったので環境構築として以下の記事も参考にさせていただいた.また,EC2 の設定としてインターネットと通信できる状態にしておくことが前提となるのでご注意ください.
こちらも Ubuntu で実行できるようコマンドをまとめておいた.
クリックすると展開されます
#!/bin/bash apt-get update apt-get install -y apt-transport-https ca-certificates curl software-properties-common jq curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" apt-get install -y docker-ce cgdb cgroup-tools uuid-runtime tree iputils-ping make gcc git clone git://git.kernel.org/pub/scm/linux/kernel/git/morgan/libcap.git /usr/src/libcap cd /usr/src/libcap make make install
NameSpace を使って隔離したネットワークからインターネットへ出ていけない
先に紹介した記事 にもある通り,NameSpace 機能で作成した Host1 や Host2 からインターネットに出ていくためには iptables による Nat を設定しなければならないのでホスト Linux 上で以下のように設定した.
iptables -t nat -I POSTROUTING -s 10.0.0.0/24 -o eth0 -j MASQUERADE
この状態で Host1 から ping を打ってみるが,インターネットへ疎通できなかった.
ip netns exec host1 ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. ...
試しに eth0,veth1,br-veth1,br-host1 のそれぞれで tcpdump をしてみてどこまでパケットが届いているか確認すると br-host1 のキャプチャでしかパケットが表示されなかった.
tcpdump -i eth0 -p icmp -n ... tcpdump -i veth1 -p icmp -n ... tcpdump -i br-veth1 -p icmp -n ... tcpdump -i br-host1 -p icmp -n 01:49:58.420877 IP 10.0.0.1 > 8.8.8.8: ICMP echo request, id 8735, seq 203, length 64 01:49:59.444910 IP 10.0.0.1 > 8.8.8.8: ICMP echo request, id 8735, seq 204, length 64

どうやら bridge 内の通信がまずうまくいっていないので以下の記事を参考にして bridge 内通信を修正.今回は Netfilter で iptables を呼ばない設定をすることにした.記事の最後にこのカーネルパラメータを 1 の状態で解決できなかった理由も書いておく.
sysctl -w net.bridge.bridge-nf-call-iptables = 0
再度各 NIC に対して tcpdump をしてみたところ veth1 までパケットが届いていることがわかった.
tcpdump -i veth1 -p icmp -n 03:06:17.104353 IP 10.0.0.2 > 8.8.8.8: ICMP echo request, id 9766, seq 1, length 64

tcpdump より veth1 から eth0 へのパケットが落ちていることが分かるので,iptables で veth1 から eth0 への FORWARD を設定した.
iptables -t filter -I FORWARD -s 10.0.0.0/24 -d 0.0.0.0/0 -j ACCEPT
eth0 の NIC を tcpdump すると Nat の設定も効いていて,インターネットから eth0 まで通信が返ってきていることを確認できた.
tcpdump -i eth0 -p icmp -n 03:12:11.326420 IP 172.30.20.98 > 8.8.8.8: ICMP echo request, id 9779, seq 1, length 64 03:12:11.328700 IP 8.8.8.8 > 172.30.20.98: ICMP echo reply, id 9779, seq 1, length 64
最後に eht0 から veth1 への戻りの FORWARD 設定をする.セキュリティも考慮してソース IP は 8.8.8.8 だけにしておく.
iptables -t filter -I FORWARD -d 10.0.0.0/24 -s 8.8.8.8/32 -j ACCEPT
そうすると Host1 からインターネットへの接続を確立できる.
ip netns exec host2 ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. 64 bytes from 8.8.8.8: icmp_seq=1 ttl=104 time=2.51 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=104 time=2.36 ms
余談
今回は bridge ネットワーク通信を正常にするために net.bridge.bridge-nf-call-iptables を 0 に設定した対応を取ったが,先の記事 にある iptables -I FORWARD -m physdev --physdev-is-bridged -j ACCEPT を iptables に設定する方法で進めてみた.
うまくいかない箇所は同じで,まずは veth1 から eth0 への通信が失敗するので iptables に iptables -t filter -I FORWARD -s 10.0.0.0/24 -d 0.0.0.0/0 -j ACCEPT を設定する.そうすると eth0 にパケットが到達するようになるが,なぜか Nat が効かない状態となる.この Nat をどうにか効かせようと色々調べて設定も変えてみたがうまくいかなかった.結果として net.bridge.bridge-nf-call-iptables=0 にする方法でうまくいったのでそちらをまとめたのだが,もし誰かこの原因をご存知の方がいたらコメント欄に書いていただけると助かります.
まとめ
- トラブルシュートしながらコンテナネットワークからインターネットへ出ていく時の設定を見つけた
- 改めてネットワークトラブルは tcpdump などでパケットを取り続けるしかないことを学んだ
net.bridge.bridge-nf-call-iptablesの設定をそのままにした状態でうまくいかない原因は明確となっていない
サーチリストを使った名前解決はやめよう
DNS を運用していると名前衝突問題に気を付ける必要がある.名前衝突問題とは,組織が内部的に使う Top Level Domain(TLD)と インターネットで利用できる TLD が重複してしまうことによりDNSの動作が期待するものとは違った動作になることを指す.名前衝突問題で具体的に問題となるのは,例えばインターネット上のドメイン名を検索するつもりが,ローカルネットワークで独自に付けたTLDに対して名前解決を行ってしまうことや,またその反対に,ローカルネットワークのドメイン名を検索するつもりがインターネット上の TLD に対して名前解決してしまうことである.JPNIC のページが詳しいのでリンクを置いておく.
今回は後者の問題である「ローカルネットワークのドメイン名を検索するつもりがインターネット上の TLD に対して名前解決してしまう」という事象を再現してみようと思う.上記の記事で紹介されているサーチリストを使ったケースを想定する.
概要
環境として使うのは AWS とし,AWS の各サービスの説明は本質的な部分とは異なるので今回は割愛する.
dig コマンドで名前解決の確認を行うために OS を Ubuntu18.04 とした EC2 を立てておく.EC2 から利用する内部的に使うドメインは Route53 で管理し, example.com という名前でプライベートホストゾーンを作成する.プライベートホストゾーンにインターネット上に存在するサブドメインを登録し,サーチリストを設定した EC2 から名前解決を行うと「ローカルネットワークのドメイン名を検索するつもりがインターネット上の TLD に対して名前解決してしまう」が再現することを確認する.
Route53 の設定
Route53 では example.com というプライベートホストゾーンを作成し,適当なプライベート IP アドレス(172.30.20.86)を指定した 2 つの A レコードを登録しておく.
aws という TLD は AWS が取得しているドメインであり, dns1.nic.aws を名前解決すると既に A レコードを正引きすることができる.
Route53 の設定を以下の図に示す.

サーチリストの設定
EC2 でサーチリストを設定する.
サーチリストは、DNS検索サフィックス、 DNS suffix search listなどとも呼ばれる、 ユーザーがドメイン名を入力する手間を減らせるようにするためのリストです。 具体的にはDNSにおいて、 名前解決の際にドメイン名を最後まで入力しなくても、 サーバやクライアントで補完がされるように、 補完候補となる文字列を順番に並べたものです。 www.nic.ad.jp
Ubuntu18.04 の場合 EC2 上で /etc/netplan/99-manual.yaml というファイル名を以下の内容で作成し再起動すればよい.
network:
ethernets:
eth0:
nameservers:
search:
- example.com
version: 2
再起動した EC2 にログインし,サーチリストを使うようにオプションをつけた dig を実行すると example.com が補完され instance-dst.example.com を名前解決できていることが確認できる.
root@ip-172-30-20-203:/etc# dig instance-dst +search ; <<>> DiG 9.11.3-1ubuntu1.16-Ubuntu <<>> instance-dst +search ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 41197 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 65494 ;; QUESTION SECTION: ;instance-dst.example.com. IN A ;; ANSWER SECTION: instance-dst.example.com. 300 IN A 172.30.20.86 ;; Query time: 2 msec ;; SERVER: 127.0.0.53#53(127.0.0.53) ;; WHEN: Sun Oct 31 08:55:09 UTC 2021 ;; MSG SIZE rcvd: 69
では,プライベートホストゾーンに登録してあるもう 1 つのサブドメインの dns1.nic.aws を名前解決してみる.
root@ip-172-30-20-203:/etc# dig dns1.nic.aws +search ; <<>> DiG 9.11.3-1ubuntu1.16-Ubuntu <<>> dns1.nic.aws +search ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 8193 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 65494 ;; QUESTION SECTION: ;dns1.nic.aws. IN A ;; ANSWER SECTION: dns1.nic.aws. 300 IN A 213.248.218.53 ;; Query time: 2 msec ;; SERVER: 127.0.0.53#53(127.0.0.53) ;; WHEN: Sun Oct 31 08:58:35 UTC 2021 ;; MSG SIZE rcvd: 57
名前解決の結果 172.30.20.86 ではなく 213.248.218.53 が返ってきている.これより,プライベートホストゾーンではなくインターネットで公開されているドメインが正引きされていることが分かる.これは,サーチリストの補完が行われる前にまずは dig コマンドで指定されたドメインが名前解決されるため, dns1.nic.aws の正引き結果が返ってきてしまっている状態である.この事象は,プライベートホストゾーンのサブドメインを運用中にそのサブドメインとインターネットに存在するドメインが重複した場合,サーチリストを設定したサーバからの名前解決が失敗する可能性があることを示している.
対策
JPNIC が紹介している対策はシンプルでサーチリストを使わないことである.
名前衝突の問題への根本的な対策は、TLDの重複を避けることです。つまり、原因となっている、内部向けのTLDやサーチリストの使用を止めることです。 www.nic.ad.jp
サーチリストを使わなければ名前解決する際に必ずプライベートホストゾーンの FQDN 指定するので,今回の事象は発生しなくなる.
まとめ
別AWSアカウントへIAMロールを提供する際は外部IDを思い出す
IAMロールでスイッチロール(マネージメントコンソールで他のAWSアカウントのロールにスイッチすること)を実現する際に「外部ID」というオプションがあったので,何のためにあるのかまとめてみた.先に言っておくとスイッチロールを使うときに外部IDを気にする必要はない.
外部IDとは
外部IDとは,第三者用のIAMロールを作成する際にセキュリティ対策用途で設定する値のことである.このセキュリティ対策は「混乱した代理」と呼ばれる問題を解決するために実施される.「混乱した代理」の概要は以下に解説されているが,この記事を通して理解できるかと思う.
以下は実際のIAMロールを作成する画面であり,外部IDを設定できることが分かる.スイッチロールを使うときに外部IDを指定する必要はない旨もかかれている.

コンソールでは、ロールの切り替え機能を使用する外部 ID の使用はサポートされていません。 画像にも書いてある通り,スイッチロールさせたいだけなら外部IDは無視して構わない.
ユースケース
スイッチロールで使わないのであれば,どんなユースケースがあるのかを考えてみる.また「混乱した代理」とその対策である外部IDがどのように機能するのか理解する.
異なる AWS アカウントで複数の顧客をサポートするマルチテナント環境では、AWS アカウントごとに 1 つの外部 ID を使用することをお勧めします。
「混乱した代理」の概要より,複数のAWSアカウントをお客様に持つサービスを提供している会社を例にとると理解しやすい.ここでは「a-mochan」という監視系のSaaSサービスがあると仮定してユースケースを説明する.「a-mochan」もAWS環境でサービス提供をしている.
「a-mochan」では,お客様のS3バケットにあるログへ定期的にアクセスし,お客様ごとにログを可視化するダッシュボードを用意している.「a-mochan」のお客様であるClient Aは自身のAWSアカウントのS3に「a-mochan」からのアクセスを許可するためにIAMロールを作成した.その際外部IDは設定しなかった.Client A は作成したIAMロールのAmazon Resource Name(arn)を「a-mochan」上で設定し,S3のデータを「a-mochan」に取り込めるようにしたことでダッシュボードを確認することができた.

ここで,悪意のあるユーザが「a-mochan」を利用し始めた.悪意のあるユーザは,IAMロールのarnが arn:aws:iam::[AWS AccountID]:role/[Role Name] のような形で推測が容易なこともあり,Client A が作成したIAMロールのarnを推測し「a-mochan」上で設定することができた.そうすると悪意のあるユーザのダッシュボードにも Client A のS3の情報が表示され,悪意のあるユーザは Client A のダッシュボードを閲覧可能な状態になる.この状態のことを「混乱した代理」と呼ぶ.

では「混乱した代理」対策のために外部IDを利用する流れをみていく.「a-mochan」はお客様ごとに一意のIDを発行し,お客様は作成するIAMロールの外部IDとして「a-mochan」が発行したIDを指定する.そうするとClient AのAWSアカウントでは「a-mochan」からのアクセス時に外部IDが一致しているかどうかチェックするようになるので,「a-mochan」ではClient AのAWSアカウントへのリクエスト時に外部IDを付与する仕様に変更する.外部IDは「a-mochan」のシステムで発行された利用者ごとに一意なIDで,利用者はコントロール不可能な値である.そのため,悪意のあるユーザが Client A のIAMロールのarnを推測できたとしても,「a-mochan」から発行されたClient A用のID(948833852)と悪意のあるユーザ用のID(749678483) が違うので「混乱した代理」は起こらない.

このように外部IDは「混乱した代理」を引き起こさないために設定する値のことであることがわかった.
感想
AWSアカウントへIAMロールを用いてアクセスさせるようなサービスを利用する時は,外部IDの発行が実装されているか確認すべきだと感じた.外部IDを考慮していないサービスはどのような方法で「混乱した代理」を回避しているのか確認して利用するサービスを選定すべきなのかなと思う.また逆も然りで,そのようなサービスを提供する時は外部IDを考慮した実装にすべきである.
まとめ
- 外部IDの意図を理解した
- 外部IDが必要となる「混乱した代理」についてユースケースを用いて理解した